
My background is grounded in DevOps and Site Reliability Engineering, and being somewhat new to the Snowflake Data Cloud world and DataOps, I have been pleasantly surprised by how much automation we can drive with a data platform like Snowflake.
Let’s first define what DataOps is: there are generally two definitions.
The first definition is the easy one, the technical one; DataOps is a way to manage your entire data infrastructure through code. This data automation includes schemas, data, testing, and all the orchestration around them in an easily manageable, fully auditable package, including governance. Andy Palmer—the person that popularized the term, said this:
“DataOps is a data management method that emphasizes communication, collaboration, integration, automation, and measurement of cooperation between data engineers, data scientists, and other data professionals.”
The second definition is the view that DataOps is a culturally-focused transformation; it is about democratizing data and using agile, collaborative methods to increase data usage while making it more reliable. This is important because many of the big data projects' problems are due to bad data, and the problem is so widespread that according to KPMG, only 6% of CEOs trust their data.
Going back to my DevOps ethos, let me refer to a DevOps Framework, CALMS, so we have a point of reference for what good looks like.
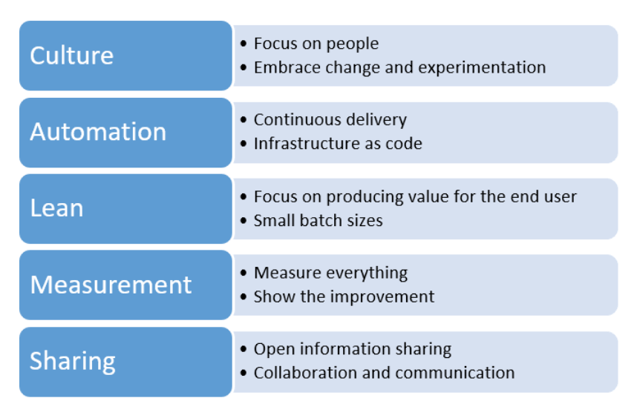
Translating this to DataOps, we could get something like this:
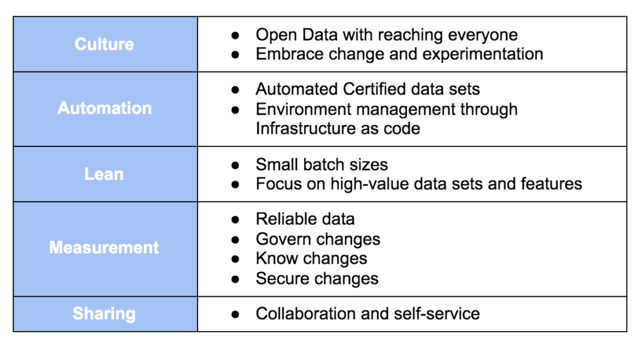
Let's review each of these points as they relate to DataOps. You will notice a pattern grounded in the Agile Manifesto. These principles reinforce the modern DataOps movement.
Culture
As I said above, Culture is an essential aspect of the Agile Manifesto, so it continues in DataOps. In my opinion, the most crucial element of DataOps is making data openly available to people. Open data does not mean open-sourcing all data. It means having readily accessible data to the data users, for example, a corporation having data readily accessible to all its employees.
This level of access to data enables change and experimentation which is so important in fostering a culture of data. You cannot achieve a culture of data without DataOps.
Automation
This topic is significant and can span many articles, but let’s consider the basics. DataOps requires that you manage all environments and their dependencies using automation. Things like Infrastructure as Code, CI/CD deployments, self-documentation via code, and automated testing for your data and transformation pipelines. This high degree of automation allows the launch of new net environments with a button, including data schema creation and data generation/restoration. For the longest time, data was considered a second-class citizen in the automation world; things have changed.
DataOps should follow the testing pyramid and use unit, functional, and UI testing. From a data perspective, tests run during builds and deployments should validate all the data objects, schemas, and views.
Using the testing Pyramid:
- Data layer (maps to Unit types testing), ETL or ELT process, confirm consistency, inconsistency, and missing data. We check for differences in row counts, partial datasets, and duplication.
- Business layer (Functional Testing) validations include validation that data is reporting within ranges of the business,
- Reporting layer (UI testing) – using visualization to confirm the data is within ranges.
Here are some data-specific products that help you accomplish these levels of automation. Some are open source, and some are paid products depending on your budget or needs:
- Data Build Tool (dbt)
- Apache Airflow
- Streamsets
- Fivetran
- Atlan
- RightData
- DataKitchen
- Prefect
You will need many current DevOps tools, Terraform and Docker being great examples.
I do not include many GUI-based products as I am not considering these proper automation tools, although many of those can probably be automated. Please comment and let me know if you have done so; I would love to hear about your experience. I define automation as things that flow through declarative workflows, i.e., GitOps.
Be Lean
Like many projects in technology, data projects fail as too much is dreamt up to be delivered. Smaller scopes are proven to deliver results faster and with better quality; the same applies to data projects. DataOps following an Agile methodology is a must-do. Pick your preferable framework; Scrum, Kanban, or Scrumban.
Most importantly, focus on high-value items and deliver quick and immediate business results and value. It is pointless to spend three years delivering a project that defines all data modeling well, figures out all security and data infrastructure, and finally goes live to something that showed zero value in three years and cost millions of dollars.
Measurement
Measurement in DataOps touches on governance in an agile manner, which means tracking changes and keeping the data and data pipeline reliable. Often, we will see unreliable data, and without proper metrics in place, it can take a long time to understand where it is coming from. Remember that only 6% of CEOs trust their data; proper governance allows you to make sure everyone in your organization trusts your data.
While the list of things you should monitor is long, you can use this list below as a guideline:
- Data Transformation error rates
- Accuracy or ratio of data to errors is a good indicator to measure
- Completeness, for example, keeps track of empty values
- Consistency is confirming that various records from different data sets match as they should
- For all these above, measure the processes over time, using ML-based tools to predict anomalies in the ingest and transformation processes.
- In general, monitor all infrastructure (cloud or on-premise, including PaaS and Saas).
- Keep track of your costs so you can adapt things to save money and detect if someone’s use case changed.
Remember to implement an SLO, and it is best to use concrete metrics to measure success. For example, you can set a target report load time of 10 seconds and measure the success of this metric.
Sharing
When my two children were growing, I often heard their daycare teachers telling them, “Sharing is caring.” The sharing principle in a DataOps world means self-service and the ability to collaborate over the data while maintaining the data’s governance. Accessible and understandable data empowers data scientists and analysts; this framework's sharing principle provides that lift.
Another important aspect of sharing is continuous improvement. As you create a culture of transparency through open sharing, your data program will continue to improve with lessons learned and retrospectives. For example, when a major failure in the ingest process happens, this could be an opportunity to retrospect the entire process and understand how this could have been prevented.
Closing Thoughts
As you enter this journey of becoming a data-driven organization, it’s important to understand the framework that can help organizations conquer this objective. DataOps is an absolute must if your organization wants to become data-driven. Using this DataOps framework borrowed from the DevOps world, your organization can step into this world with confidence that your data program will succeed.
Recap
The benefits of adopting a DataOps Framework are:
- A successful data program with higher adoption rates
- A resilient data platform focused on business value
- A continuously improving data program through a balance of governance and agility
To explore this topic further, check out Infostrux’s upcoming articles on DataOps.
Sources:
https://hbr.org/2020/02/10-steps-to-creating-a-data-driven-culture
https://towardsdatascience.com/a-deep-dive-into-data-quality-c1d1ee576046


